
Agent Prune: A Robust and Economic Multi-Agent Communication Framework for LLMs that Saves Cost and Removes Redundant and Malicious Contents


“If you want to go fast, go alone. If you want to go far, go together”: This African proverb aptly describes how multi-agent systems outperform regular individual LLMs in various reasoning, creativity, and aptitude tasks. Multi-agent(MA) systems harness the collective intelligence of multiple instances of LLMs via meticulously designed communication topologies. Its outcomes are fascinating, with even the simplest communications notably increasing accuracy across tasks. However, this increased accuracy and versatility comes at a price, this time with increased token consumption. Studies show that these communication methodologies could increase the cost from twice to almost 12 times the regular token consumption, severely undermining the Token Economy for multi-agents. This article discusses a study that catches a caveat in current communication topologies and proposes a solution so agents can go far together, all while cutting down on fuel.
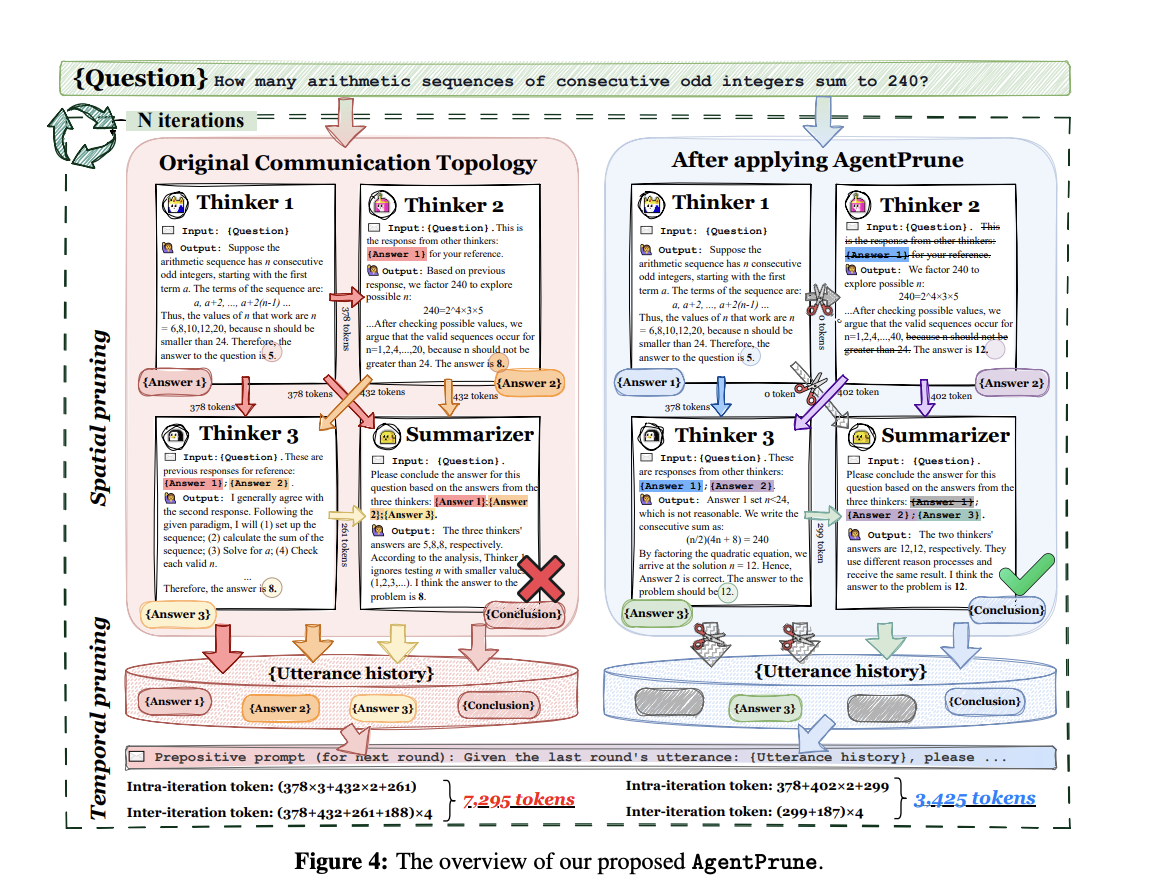
Researchers from Tongji University and Shanghai AI Laboratory coined the concept of Communication Redundancy within the communication topologies of multi-agents. They realized that a substantial chunk of message passing between agents does not affect the process. This realization inspired AgentPrune, a communication pruning framework for LLM-MA.AgentPrune treats the whole multi-agent framework as a spatial-temporal communication graph and uses a communication graph mask with a low-rank principle to solve the issue of communication redundancy. Pruning occurs in two ways: (a) Spatial pruning to remove redundant spatial messages in a dialogue and ( b) temporal pruning to remove irrelevant dialogue history.
It would be worthwhile to understand the two central communication mechanisms before diving into AgentPrune’s technicalities. There are two kinds of communication strategies between agents. The first is Intra-dialogue communication, where agents collaborate, teach, or compete during a single session. Inter-dialogue communication, on the other hand, occurs between multiple rounds of dialogue where the information or insights from that interaction are carried over to the next agent. Now, in the spatial-temporal graph analogy of AgentPrune, nodes are agents along with their properties, such as external API tools, knowledge base, etc. Further, Intra-dialogue communication constitutes the spatial edges, and Inter-dialogue communication forms the temporal edges. AgentPrune’s low-rank principal guided masks identify the most significant entities and retain them by one-shot pruning, yielding a sparse communication graph that beholds all the information.
The algorithm is handy and easy to incorporate into existing LLM MA. It is like a plug-and-play module for agents to optimize token consumption and have the best of both worlds. However, the number of agents must exceed three, and the communication must be moderately structured to use it. Agent Prune also undergoes Multi-Query Training to optimize the number of queries and solve the problem, providing the minimum necessary ones.
This new pipeline was tested on tasks of General Reasoning, Mathematical Reasoning, and Code Generation with notable datasets. AgentPrune was added to an MA system of 5 GPT-4 models. The following were the significant insights:
A) Not all multi-agent topologies consistently delivered better performance.
B) High-quality Performance was achieved with saved costs, thus achieving utility and savings.
Additionally, AgentPrune removed malicious messages to ensure its robustness under adversarial attacks. It was verified when authors engineered agent prompt and agent replacement adversarial attacks, and yet the system didn’t face a significant decline in contradistinction to the case without AgentPrune.

AgentPrune streamlines the interactions and workings of MA, ensuring accuracy while saving tokens. Its CUT THE CRAP strategy proposes a frugal approach to accuracy in this world of extravagance.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.

Comments are closed, but trackbacks and pingbacks are open.