
DataVisT5: A Powerful Pre-Trained Language Model for Seamless Data Visualization Tasks



Data visualizations (DVs) have become a common practice in the big data era, utilized by various applications and institutions to convey insights from massive raw data. However, creating suitable DVs remains a challenging task, even for experts, as it requires visual analysis expertise and familiarity with the domain data. Also, users must master complex declarative visualization languages (DVLs) to accurately define DV specifications. To lower the barriers to creating DVs and unlock their power for the general public, researchers have proposed a variety of DV-related tasks that have attracted significant attention from both industry and academia.
Existing research has explored various approaches to mitigate the challenges in data visualization-related tasks. Initial text-to-vis systems relied on predefined rules or templates, which were efficient but limited in handling the linguistic variability of user queries. To overcome these limitations, researchers have turned to neural network-based methods. For example, Data2Vis conceptualizes visualization generation as a sequence translation task, employing an encoder-decoder neural architecture. Similarly, RGVisNet initiates the text-to-vis process by retrieving a relevant query prototype, refining it through a graph neural network model, and then adjusting the query to fit the target scenario. Concurrently, vis-to-text has been proposed as a complementary task, with performance improvements demonstrated through a dual training framework. Researchers have also defined the task of free-form question answering over data visualizations, aiming to enhance the understanding of data and its visualizations. Also, several studies have focused on generating textual descriptions for data visualizations, adopting sequence-to-sequence model frameworks and employing transformer-based architectures to translate visual data into natural language summaries.
Researchers from PolyU, WeBank Co., Ltd, and HKUST propose an effective pre-trained language model (PLM) called DataVisT5. Building upon the text-centric T5 architecture, DataVisT5 enhances the pre-training process by incorporating a comprehensive array of cross-modal datasets that integrate natural language with data visualization knowledge, including DV queries, database schemas, and tables. Inspired by large language models that have incorporated programming code into their pre-training data, the researchers employ CodeT5+ as the starting checkpoint for DataVisT5, as it has been trained on code data. To reduce training complexity, the researchers apply table-level database schema filtration. To overcome the format consistency challenges between the data visualization and textual modalities, DataVisT5 introduces a unified encoding format for DV knowledge that facilitates the convergence of text and DV modalities. Also, the pre-training objectives for DataVisT5 include the span corruption approach of Masked Language Modeling (MLM) as utilized by the original T5 model, as well as a Bidirectional Dual-Corpus objective that operates on source-target pairings. After the mixed-objective pre-training, the researchers conduct multi-task fine-tuning of DataVisT5 on DV-related tasks, including text-to-vis, vis-to-text, FeVisQA, and table-to-text.
Concisely, the key contributions of this research are:
- Researchers introduced and released DataVisT5: the first PLM tailored for the joint understanding of text and DV.
- Enhanced the text-centric T5 architecture to handle cross-modal information. Their hybrid pre-training objectives are conceived to unravel the complex interplay between DV and textual data, fostering a deeper integration of cross-modal insights.
- Extensive experiments on public datasets for diverse DV tasks including text-to-vis, vis-to-text, FeVisQA, and table-to-text demonstrate that DataVisT5 (proposed method) excels in multi-task settings, consistently outperforming strong baselines and establishing new SOTA performances.
Researchers have also provided basic definitions of various fundamental data visualization-related concepts so that users will have a profound understanding of the proposed method.
Natural language questions enable users to formulate queries intuitively, even without specialized DV or programming skills. Declarative visualization languages, such as Vega-Lite and ggplot2, provide a set of specifications to define the construction of visualizations, including chart types, colors, sizes, and other visual properties. Visualization specifications, encoded in JSON format, describe the dataset and its visual attributes according to the syntax of a specific DVL. The data visualization query framework introduces a SQL-like query format to encapsulate the full spectrum of potential DVLs, allowing for conversion between different visualization specifications. Finally, the data visualization charts are the visual representations, such as scatters, bars, or maps, that convey the summarized data and insights defined by the visualization specification.
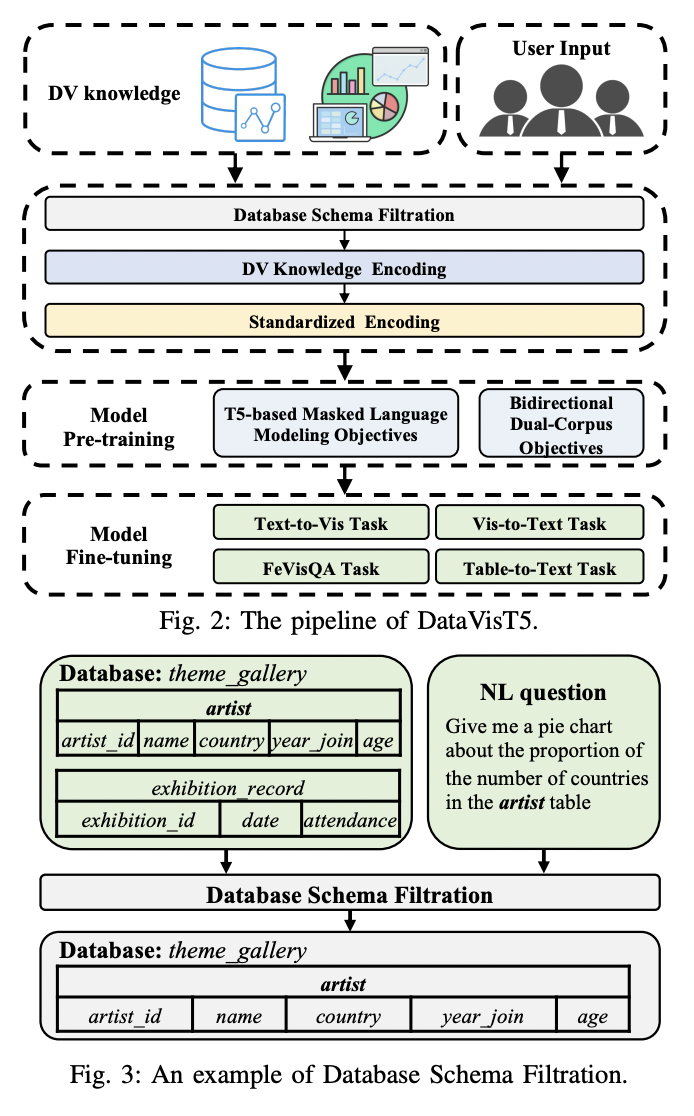
The proposed method DataVisT5, follows a comprehensive pipeline comprising five main stages: (1) Database schema filtration, (2) DV knowledge Encoding, (3) Standardized Encoding, (4) Model Pre-training, and (5) Model Fine-tuning. The database schema filtration process identifies the referenced tables in the given natural language question by comparing n-grams extracted from the database schema with those in the text. This allows the acquisition of a sub-database schema that is semantically aligned. The DV knowledge encoding phase then linearizes the DV knowledge, including DV queries, database schemas, and tables, into a unified format. The standardized encoding stage normalizes this DV knowledge to facilitate more efficient learning. The resulting corpus, in its unified form, is then used to pre-train the proposed DataVisT5 model. Finally, the pre-trained DataVisT5 undergoes multi-task fine-tuning on various DV-related tasks.
Database schema filtration technique matches n-grams between the natural language question and database tables, identifying relevant schema elements and extracting a sub-schema to minimize information loss during the integration of data visualization and text modalities.
To tackle the text-DV modality gap, the researchers propose a unified format for DV knowledge representation, enabling models to utilize extensive pre-training on smaller datasets and mitigating performance decline from data heterogeneity during multi-task training.
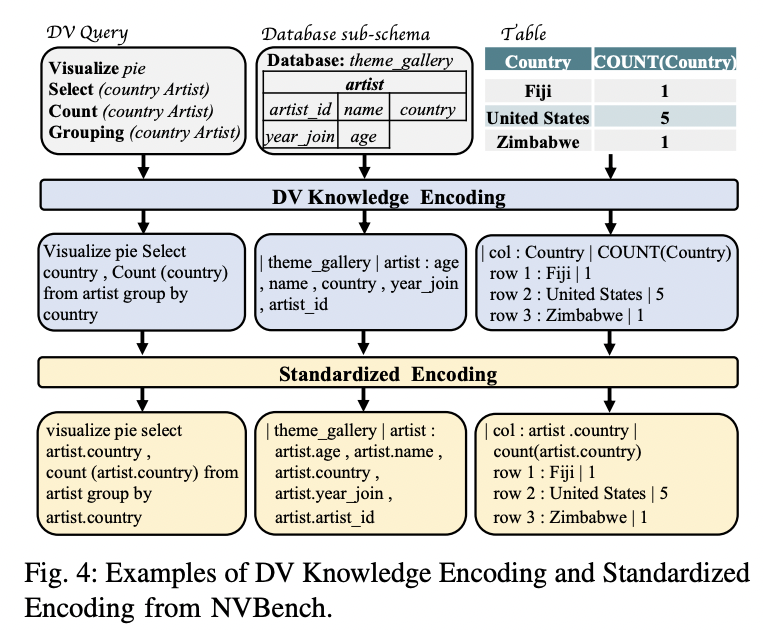

To mitigate the stylistic inconsistencies in the manually generated data visualization queries, the researchers implemented a preprocessing strategy. This includes standardizing the column notation, formatting parentheses and quotes, handling ordering clauses, replacing table aliases with actual names, and converting the entire query to lowercase. These steps help mitigate the learning challenges posed by the diverse annotation habits of multiple annotators, ensuring a more consistent format for the DV knowledge.

The researchers employ a bidirectional dual-corpus pretraining strategy, where the model is trained to translate randomly selected source and target corpora in both directions, enhancing the model’s ability to learn the relationship between text and data visualization knowledge.
The researchers employ temperature mixing to combine training data from all tasks, balancing the influence of each task and encouraging the model to learn representations beneficial across various corpora, leading to improved generalization and robustness in handling diverse data visualization tasks.
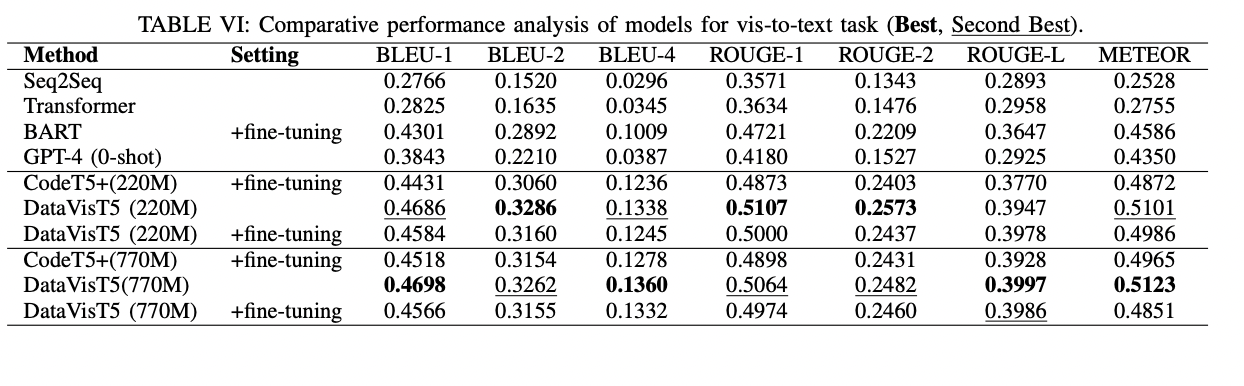
DataVisT5 demonstrates significant improvements over existing techniques like Seq2Vis, Transformer, RGVisNet, ncNet, and GPT-4. In extensive experiments, this approach achieved a remarkable 46.15% increase in the EM metric on datasets without join operations compared to the previous state-of-the-art RGVisNet model. Also, DataVisT5 outperformed the in-context learning approach using GPT-4 in scenarios involving join operations, enhancing the EM metric by 44.59% and 49.2%. Notably, in these challenging join operation scenarios where other models have historically struggled, DataVisT5 achieved an impressive EM of 0.3451. The ablation study highlights the effectiveness of the proposed approach, with finetuned models of 220M and 770M parameters consistently outperforming the finetuned CodeT5+ model. These results underscore the superior comprehension of DataVisT5 when it comes to DV query syntax and semantics, benefiting from the hybrid objectives pre-training.

In this study, the researchers have proposed an effective pre-trained language model called DataVisT5, specifically designed to enhance the integration of cross-modal information in DV knowledge and natural language associations. DataVisT5 introduces a unique mechanism to capture highly relevant database schemas from natural language mentions of tables, effectively unifying and normalizing the encoding of DV knowledge, including DV queries, database schemas, and tables. The robust hybrid pre-training objectives employed in this model help unravel the complex interplay between DV and textual data, fostering a deeper integration of cross-modal insights.
By extending the text-centric T5 architecture to adeptly process cross-modal information, DataVisT5 addresses multiple tasks related to data visualization with remarkable performance. The extensive experimental results demonstrate that DataVisT5 consistently outperforms state-of-the-art models across a wide range of DV tasks, expanding the applications of pre-trained language models and pushing the boundaries of what is achievable in automated data visualization and interpretation. This research represents a significant advancement in the field and opens up new avenues for further exploration and innovation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.


Comments are closed, but trackbacks and pingbacks are open.