
Quanda: A New Python Toolkit for Standardized Evaluation and Benchmarking of Training Data Attribution (TDA) in Explainable AI


XAI, or Explainable AI, brings about a paradigm shift in neural networks that emphasizes the need to explain the decision-making processes of neural networks, which are well-known black boxes. In XAI, methods of feature selection, mechanistic interpretability, concept-based explainability, and training data attribution (TDA) have gained popularity. Today, we talk about TDA, which aims to relate a model’s inference from a specific sample to its training data. Apart from model explainability, it also helps with other vital tasks such as model debugging, data summarization, machine unlearning, dataset selection, fact tracing, etc. Research on TDA is thriving, but we see meager work in evaluating attributions. Several standalone metrics have been proposed to assess the quality of TDA across contexts; however, they do not provide a systematic and unified comparison that could gain the trust of the research community. This calls for a unified framework for TDA evaluation (and beyond).
The Fraunhofer Institute for Telecommunications has put forth Quanda to bridge this gap. It is a Python toolkit that provides a comprehensive set of evaluation metrics and a uniform interface for seamless integration with current TDA implementations. This is user-friendly, thoroughly tested, and available as a library in PyPI. Quanda incorporates PyTorch Lightning, HuggingFace Datasets, Torchvision, Torcheval, and Torchmetrics libraries for seamless integration into users’ pipelines while avoiding reimplementing available features.
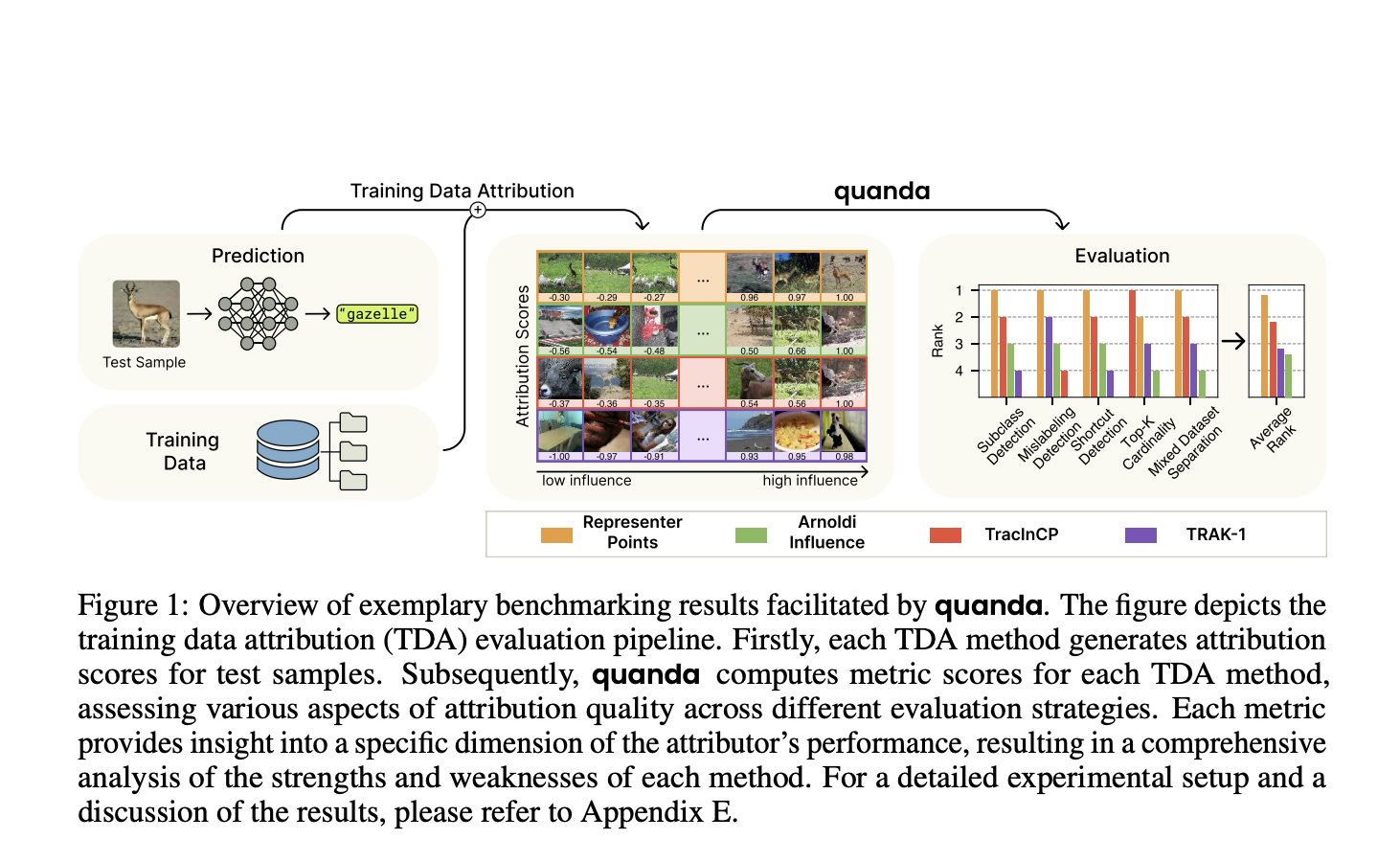
TDA evaluation in Quanda is comprehensive, beginning with a standard interface for many methods spread across independent repositories. It includes several metrics for various tasks that allow a thorough assessment and comparison. These standard benchmarks are available as precomputed evaluation benchmark suites to ensure user reproducibility and reliability. Quanda differs from its contemporaries, like Captum, TransformerLens, Alibi Explain, etc., in terms of the extensivity and comparability of evaluation metrics. Other evaluation strategies, such as downstream task evaluation and heuristics evaluation, fail due to their fragmented nature, single comparisons, and lack of reliability.
There are several functional units represented by modular interfaces in the Quanda library. It has three main components: explainers, evaluation metrics, and benchmarks. Each element is implemented as a base class that defines the minimal functionalities needed to create a new instance. This base class design permits users to evaluate even novel TDA methods by wrapping their implementation in accordance with the base explainability model.
Quanda is built on Explainers, Metrics, and Benchmarks. Each Explainer represents a specific TDA method, including its architecture, model weights, training dataset, and so on. Metrics summarize the performance and reliability of a TDA method in a compact form.Quanda’s stateful Metric design includes an update method for accounting for new test batches. Additionally, a metric can be categorized into three types: ground_truth, downstream_evaluation, or heuristic. Finally, Benchmark enables standard comparisons across different TDA methods.
An example usage of the Quanda library to evaluate concurrently generated explanations is given below:

Quanda addresses the gaps in TDA evaluation metrics that led to hesitancy in its adoption within the explainable community. TDA researchers can benefit from this library’s standard metrics, ready-to-use setups, and consistent wrappers for available implementations. In the future, it would be interesting to see Quanda’s functionalities extended to more complex areas, such as natural language processing.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.

Comments are closed, but trackbacks and pingbacks are open.