
This AI Paper from Google DeepMind Explores Inference Scaling in Long-Context RAG

Long-context Large language models (LLMs) are designed to handle long input sequences, enabling them to process and understand large amounts of information. As the interference computation power is increased the large language models (LLMs) can perform diverse tasks. Particularly for knowledge-intensive tasks that rely mainly on Retrieval augmented generation (RAG), increasing the quantity or size of retrieved documents up to a certain level consistently increases the performance. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge. However, just adding more amount of information does not always enhance performance. Numerous studies have also shown reading more information can also add noise and thus it may even cause performance degradation. As a result, inference scaling of long-context RAG remains challenging for existing methods.
Early works in extending context lengths involve techniques like sparse / low-rank kernels to reduce memory requirements. In addition to this, recurrent and state space models (SSMs) are proposed as efficient substitutes for transformer-based models. Recent advancements in efficient attention methods further enable LLMs to train and infer upon input sequences comprising millions of tokens. In-context learning (ICL) is a way to make models more efficient by showing them a few examples of the task during inference (when they’re processing responses). To further improve ICL performance, existing works focus on pretraining methods that optimize the language models to understand and learn in context. With the emergence of long-context LLMs scaling the number of examples becomes possible in ICL. Retrieval augmented generation (RAG) improves language model performance by useful information from external sources. Instead of just using random information or data, improving how the model picks relevant documents helps it generate better answers and better predictions. In addition, encoding documents can increase knowledge retrieval and generate more accurate information. Recently, methods for handling large and long documents and scaling up storage for retrieved data have been proposed to make RAG even better at performance.
Despite such progress, inference scaling remains under-explored for long-context RAG methods in knowledge-intensive settings. To bridge this gap, researchers investigated how variations in inference computation impact RAG performance, intending to optimize test-time compute allocation in downstream tasks.
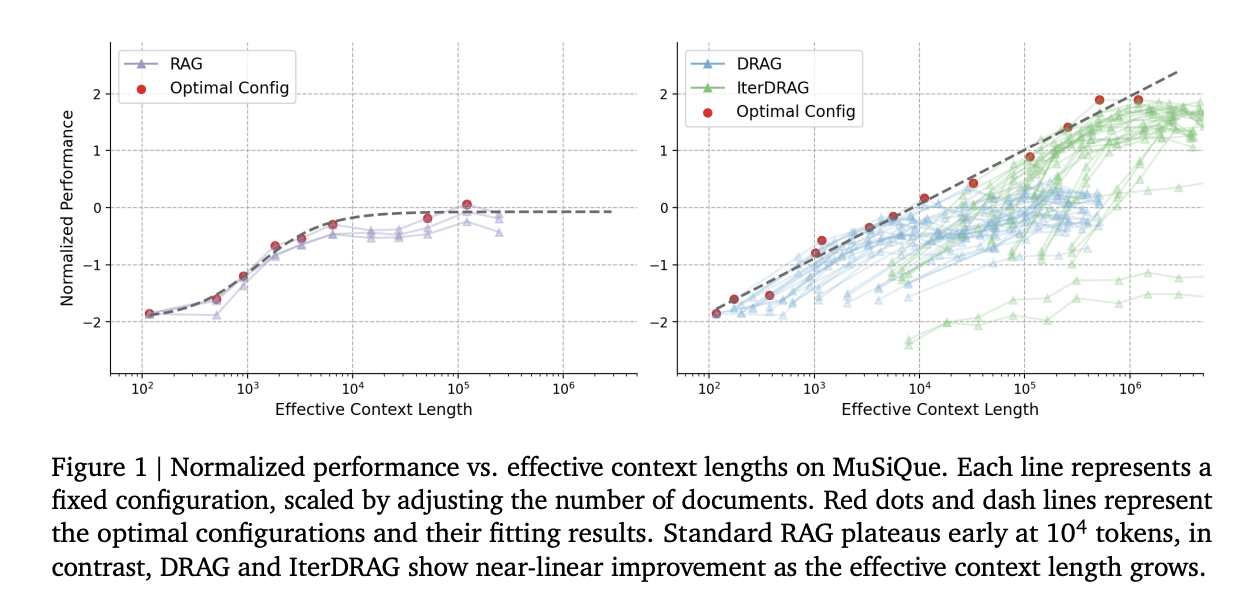
A group of researchers from Google DeepMind, the University of Illinois, Urbana-Champaign, and the University of Massachusetts Amherst studied inference scaling for Retrieval augmented generation (RAG), exploring methods that are beyond simply increasing the amount of data. They mainly focused on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation, thereby enhancing LLMs’ ability to effectively acquire and utilize context-related information. The observations of research revealed that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship described as the inference scaling laws for RAG. Building on this, they further developed the computation allocation model to estimate RAG performance across different inference configurations. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. The researchers used a simple approach by introducing Demonstration-based RAG (DRAG), where multiple examples are taken to teach the model how to find and apply relevant information. While DRAG helps, one-time retrieval often doesn’t give enough information for more complex tasks. To solve this, they developed Iterative DRAG (IterDRAG), which breaks down queries into smaller parts, retrieves information in steps, and builds up answers by reasoning through these smaller queries which helps the models handle more complex tasks. In IterDRAG, the number of steps that the model takes to generate an answer can also be extended. The experiments showed that by scaling up the amount of computing used, both DRAG and IterDRAG consistently improved their performance, with IterDRAG performing even better by retrieving and generating in steps. This shows a near-linear improvement in RAG performance as we increase the computing power, especially when the right settings are used. This iterative process helps handle more difficult tasks by focusing on each sub-part of the query. Both methods scale inference computation, improving performance by making better use of context and retrieved knowledge.


The researcher evaluated the performance of different Retrieval-Augmented Generation (RAG) strategies across various computational budgets. It was found that upon comparison, the DRAG and IterDRAG exhibit superior scalability compared to QA and RAG baselines, with DRAG excelling at shorter context lengths (up to 32k tokens) and IterDRAG performing better with longer contexts (up to 5M tokens). The performance of DRAG continues to improve until 1M tokens, while IterDRAG benefits from iterative retrieval and generation with even larger budgets. The observations revealed that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying the optimal configurations, they demonstrate that scaling inference computed on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
In conclusion, the introduction of two innovative strategies, DRAG and IterDRAG, are designed by the researchers to enhance the computing efficiency for Retrieval-Augmented Generation (RAG). Through experimental validation, they demonstrated that these strategies significantly outperform the traditional approach of merely increasing the number of retrieved documents. Based on the observations, they derived inference scaling laws for RAG and the corresponding computation allocation model, designed to predict RAG performance on varying hyperparameters. Through extensive experiments, it showed that optimal configurations can be accurately estimated and aligned closely with the experimental results. These insights can provide a strong foundation for future research in optimizing inference strategies for long-context RAG.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.

Comments are closed, but trackbacks and pingbacks are open.